
In March 2016 an algorithm created by Google’s DeepMind called AlphaGo beat a world champion Lee Sedol in a game called Go.
Go is a board game with quite simple rules. In China, this game is played for over 3000 years (there are even specialized schools that train Go players). What exactly happened? Why this event made so many headlines and why all scientific environments around machine learning and Artificial Intelligence consider this a big breakthrough that nobody considered to happen for at least another decade?
So what happened?
Despite the simplicity of Go rules (players are placing black and white stones on board, the goal is to possess as much territory as possible), the game has more board configurations than there are atoms in the universe. To compare:
Go possible moves: 10^{170}
Atoms in the universe: 10^{80}
It is simply impossible to write any brute force solution. Any attempts so far did not even allow to achieve nearly good results of the average player. Instead of this DeepMind’s team used Reinforcement Learning with Neural Networks to mimic the process of learning in a human brain. The algorithm allows an Agent to play itself and depending on received rewards with time it figures out what are the rules and how to find a good policy to act.

AlphaGo in the first phase of the project was shown raw pixels of 100k games of human average players found on the internet. In the second phase of the project, AlphaGo played against itself for 10M times. This took a few days of training and was enough to beat the best human player. Of course, it is not the first time in history that a computer can beat a human player. But in this case, we have a proof that a machine can truly learn from its own experience (it saw only raw pixels and played against itself), figured out without any human help rules of the game, approximated human intuition and in relatively short time outperformed best human player. It also created some strange and new moves (shows that it is creative by developing its own strategies – something that we thought only humans can do). It allowed AlphaGo to win 4 of 5 matches against Lee Sedol. Nowadays those moves are used in Go schools in China to train students and expand their way of thinking.
It is something that no one expected to happen so fast and also a game of Go was considered a holy Grail of Artificial Intelligence.
DeepMind’s research work and achievements started to be a very hot topic in the AI community. Many people, companies, and universities started their own researches. Since then was published many papers, new RL algorithms, and many new amazing breakthroughs. DRL is currently one of the most promising and actively researched filed in AI.
What exactly is Deep Reinforcement Learning?
Reinforcement Learning in its definition is learning to optimize rewards. We have some agent that operates in a particular environment. After each action, it receives some rewards and environment observations. The objective of an agent is to act in the way to maximize rewards. The key to the success of DeepMinds algorithm was merging this technique with the power of Deep Learning and Neural Networks.
We can say that reward is the central thing in Reinforcement Learning. Reward obtained by an agent should reinforce its behavior to maximize rewards in the future. It gives feedback to the agent if its previous action was good or bad. This is the way that human beings learn. Every time we sense some pleasure our brain reacts to some specific chemicals (like Dopamine, Serotonin, and many others) and this reinforces these certain actions. And the same with the opposite. If we experience some pain, anxiety, or fear there is a much lower possibility that we will perform the same action in the future.
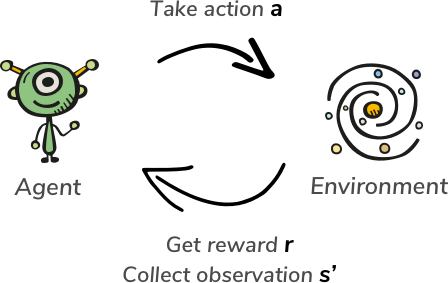
As mentioned earlier our algorithm consists of an Agent that interacts with some environment. Agent see the state of the environment and decides what action to take. After performing this step he received from the environment a new state and the reward (that means if the action was good or bad).
After repeating this process many times Agent will explore enough states of the environment and will be able to create a Policy on how to act.
How can we use Deep Reinforcement Learning for Business or Scientific use cases?
- Robotics – this is a very good use case for Reinforcement Learning. Here we can treat the real world as an environment. Robot can perform some actions, perceive the world by the camera and set of sensors. It can receive rewards depending if it completed the desired action or failed (in practice they are never learning from scratch in the real environment because it would be too expensive if it’s destroyed while training and learning can not be fasten – it can learn only in a real-time)
- Game bots – this is the most popular example of the application of Deep Reinforcement Learning. Here we have a working environment, defined set of actions. It is relatively easy to compute and train agents. Most of RL research papers are showing algorithms playing old school Atari games.
- Medicine discoveries – RL algorithms help to design better drug discoveries or help to tackle a very important problem of protein folding. The most famous example of this is again DeepMind’s program called AlphaFold. in December 2018 they took part in a famous protein folding competition CASP13. AlphaFold outperformed dramatically all other competitors that are researching this field for many years. If you are interested in this topic you can check DeepMind’s blog post at this link.
- Trading stocks – agent can observe stock market prices. Depending on observations decide to buy or to sell. This kind of program can make decisions very fast (even in milliseconds – that in the professional trading industry may be very important)
- Price optimization – this is a perfect task for Reinforcement Learning as it in definition has that it is learning to optimize rewards. We can think of revenue as a reward. This field is quite complicated. Not always selling the biggest amount of products equals the maximum possible revenue. So there are a lot of complicated mathematical and statistical equations. But systems build on top of that do not react on constant market changes and do not take into account all variables that have an influence on the final results (some of them are not even measurable). Deep Reinforcement Learning Algorithms are constantly learning. And it not only means that they are getting better and better with time but also quickly adapt to changes (for example customer’s preferences change connected to fashion or something else that can influence people’s decisions). These agents are capable to learn some patterns in data that we do not know directly and it allows them to adapt to those changes on the market (in Machine Learning terminology it is called hidden dimension)
- Managing systems – Google has a system that manages power on its servers using Reinforcement Learning. They report that using it helped significantly decrease power consumption in their centers.
- Neural Networks architecture search – for researchers to find an optimal set of all hyperparameters to train neural networks is a lot of work without a promise that their solution is optimal. And to check if the chosen set of hyperparameters is good there is a need to train such a network which is very computation and time-consuming. Using Reinforcement Learning for this turned out to give very good results
- Recommendations systems – a lot of recommendation system like advertisements, movies, music, shopping advisors are successfully using RL
Case study for Deep Reinforcement Learning in stock market trading
Ok, so now if we have some theoretical knowledge let’s try to do something in practice. We will try to build a stock market trading bot. Of course, it will be a very simplified example. Otherwise, we would not be able to fit in the size of this article. The stock trading market is known for being noisy and stochastic environment. It requires a lot of work to possess as much as possible meaningful data. On a very simplified environment and simplified data, we will show that an agent actually can learn for himself without prior expert knowledge only receiving a reward signal if he has done something good or bad. But for sure it will not be a “Wall Street killer” so please do not use it for real trading 🙂
IMPORTANT!!! The next part of the article will require basic knowledge of programming in python as well as basic concepts of building and training artificial neural networks. If you are not a programmer or don’t know basic concepts of Data Science you can skip this part and go directly to the results section below – which should be understandable for everybody.
Code for this article is available on GitHub at this link.
Our Policy can be a mathematical equation and use the Bellman equation of optimality to solve it (this article is too long to take a deeper look here, but if you are interested you can read about it at this link). It is called the Reinforcement Learning algorithm. Or instead of a mathematical equation, we can use an artificial neural network that will learn the optimal policy. This kind of algorithm is called Deep Reinforcement Learning.
There are several ways we can divide types of RL algorithms. One distinguishes them depending on if they are value-based od policy-based.
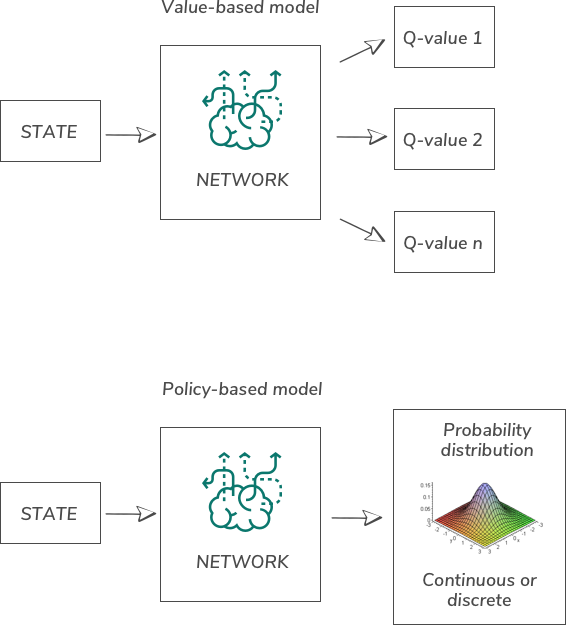
The objective of the value-based model is to learn how to estimate the value of each action. And the policy-based model returns probability distribution what action should be taken. This means that this algorithm is trying to learn policy directly instead of guessing the values of each action.
The algorithm used in our example is called PPO (Proximal Policy Optimization). We will use Stable Baselines implementation. It is a hybrid mixture of value and policy-based models. It was proposed by the OpenAI team in 2017 link. PPO is an extension of A2C (Advantage Actor-Critic) RL algorithm. The general scheme for A2C and PPO looks like this:
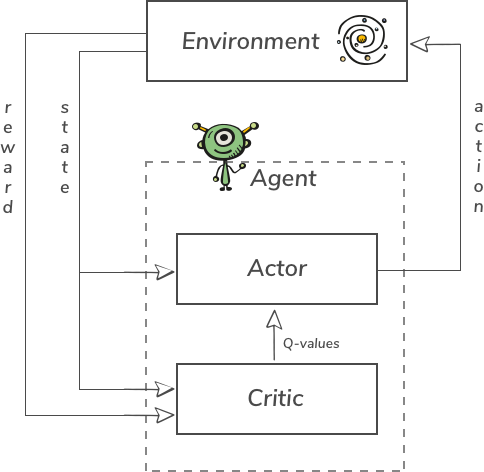
So here, we see that Agent consists of two parts: Actor and Critic. They are two separate neural networks.
A Critic model is a value-based model. It outputs Q-values – this means it is predicting the value of each possible action. The main mechanism of training is actually borrowed from supervised learning. Our model outputs what it predicts the next Value of the State will be. But after executing action we already know the reward and see if the prediction was correct (before training we are running several episodes and store all states, actions, and rewards). So like in supervised learning we have predicted value and target value. We can apply standard Stochastic Gradient Descent here.
Also at the end of each episode from the output of this network we can count Advantage (useful for Actor network), showing if taken actions were better or worse than what what was expected:
Q-value is what our network predicts as G_{t} – sum of discounted rewards obtained during one episode. Discount rate () is one of the hyperparameters of the model. Usually, it is between 0.9 and 0.99. Applying it basically means that rewards obtained at the beginning of the episode will not be so important to the Agent as the ones in the end. By tweaking this hyperparameter you can control “how greedy” agent will be for instant rewards or it will be able to build policy focused to maximize final reward in the future. It is a very interesting hyperparameter because it can change Agent behavior.
An Actor model is a policy network that acts like a standard policy gradient algorithm. It returns probability distribution what action should be taken. Its objective function tries to learn an optimal control policy. When going about policy gradients the most simple Vanilla Policy Gradient objective function looks like this:
In this equation \pi _{\theta } is our policy and \theta are parameters of the model. Training this function works by applying the Stochastic Gradient Ascent algorithm. It works exactly like Stochastic Gradient Descent but we are tweaking parameters in the direction where gradient grows instead of going lower. This is because we are not minimizing loss function but trying to make better actions more likely in the future. Pay attention to this because it is a very common mistake during the implementation of any Policy Gradient algorithm. If Advantage is positive we count gradients with backpropagation and change all parameters of the network to make this action more possible in the future. If the advantage was negative action will become less probable.
The biggest problem with this Vanilla Policy Gradient is that it directly depends on the advantage \hat{A}_{t} . It means that surprisingly better or worse actions than expected can change too much and completely ruin already learned policy. The objective function is noisy and we do not want to destroy policy based on one single action. PPO has a clipping hyperparameter. This mechanism ensures that the updated policy will not jump too far away from the current one. If you are interested about this in more details (because PPO has several more modifications that we do not discuss in this article) you can check these videos:
https://www.youtube.com/watch?v=5P7I-xPq8u8
https://www.youtube.com/watch?v=bRfUxQs6xIM&list=PLqYmG7hTraZBKeNJ-JE_eyJHZ7XgBoAyb&index=6)
or paper published by OpenAI: https://arxiv.org/pdf/1707.06347.pdf.
The final PPO objective function (that does not allow for too big policy jumps) looks like this:
- \theta is the policy parameter
- \hat{E}_{t} denotes the empirical expectation over timestamp
- r_{t} is the ratio probability under the new and old policies, respectively
- \hat{A}_{t} is the estimated advantage at time t
- \epsilon is a hyperparameter, usually 0.1 or 0.2
As we discussed the most important details now we can take a look at the updated schema of model:
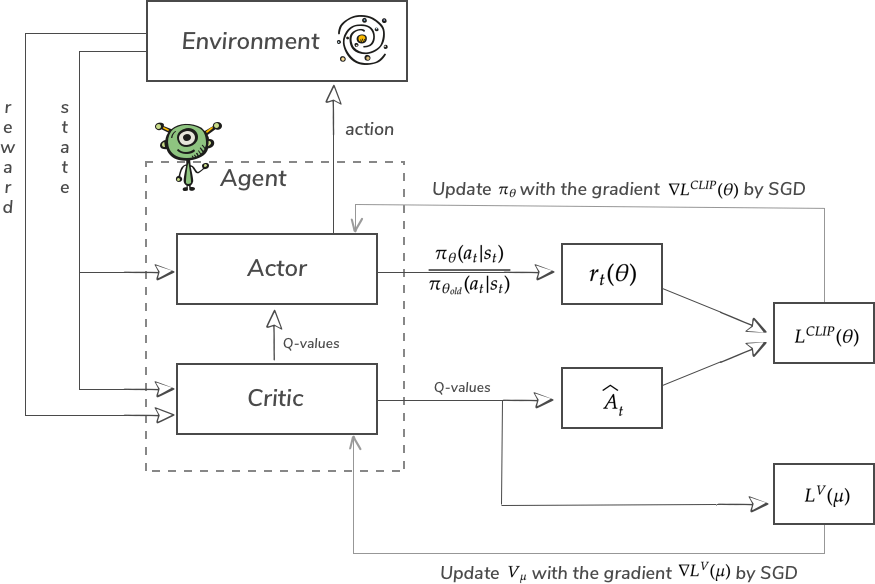
Model of network
We are using Stable Baselines implementation and we can choose between several types of network architectures. Stock market data are time-series data. Their meaning highly depends on the order. This is why we need to use a recurrent network architecture. With Stable Baselines, we can choose MlpLstmPolicy (link)
Environment
To train agent we need some environment that it can interact with. We won’t go deep about its implementation and for simplicity of the example, we will treat it like a black box. If you are interested in it you can find it on GitHub repo in a file called env.py
Our environment is the stock trading market. It is implemented with the OpenAI Gym API. The Gym is a Python library from the OpenAI company created by Elon Musk. It provides a list of many ready environments as well as API to create your own.
Elements of environment:
Action space – there may be many types and shapes of action spaces (discrete, continuous, hybrid). In our example it is simple. Agent can: Buy, Close or Skip
and in the constructor we have to define action space like this:
Observation space – for trading observations will be data from market – like prices of shares, etc. Our data looks like this:

Data is very simple. We have standard stock market Open, High, Low, and Close values as well as Volume which indicates how much movements were over this stock during the time step. Additionally, we add there current profit and account balance. It is very little because stock markets in real life are very complex. There are many players that in fact interact with each other. Prices react to what other agents do, on some worldwide or local events and news. Human psychological biases are known to have a huge impact on stock market behaviors. So including in observations as much as possible other stock movements and some sentiment analysis of correlated news would have a huge impact on our agent success.
In environment constructor we have to define observation space like this:
reset() function – after each episode resets env to initial state
step() function – allows to perform chosen action and check it’s outcome like: reward, next observation, information if episode is over
reward – float value. As a reward is a central thing in Reinforcement Learning shaping rewards can have deciding the impact of training success. For example, in our case, we have a lot of possibilities on how to return rewards. It can be pure profit, account balance, how much we earned comparing to previous time step or profit movements expressed in percentage values. It can also be a more complicated mathematical function like these ones in Adam King’s article Reward Optimization part.
done – flag that tells if episode is finished
render() – this method allows to show what is going on in the environment. Can be in a visual way or printing some values. But it is not required to implement.
Final model and training code
As you can see building model and running training with Stable Baselines is quite clear. All these hyperparameters that are provided here are obtained by running an Optuna hyperparameters optimization. Deep Reinforcement Learning is generally suffering from high sensitivity for hyperparameter tuning. It is very likely that you will not be able to find a good hyperparameters space for your model without some kind of optimization technique. If you are interested in how it was done for this model you can check Optuna. These computations may take even a few days so you have to think good what parameters to search, in what ranges, and for how many steps. This will highly influence the time of execution.
Evaluation
We have training data for five instruments on the stock market. Each of them is divided into training and evaluation data sets. For each of these instruments, we run 1M training steps, and then we run an evaluation on unseen data to check if the model is not overfitting. Evaluation code:
Summary
As we can see here episode rewards during training agent on the first instrument and the last one visibly improved:

This means that even with so primitive data our agent is able to learn only receiving rewards signal, which I think is incredible! 🙂
By looking on the validation data we can see that our agent learned how to become profitable with time:

An example is very simplified and as we know markets are large and complex. We did not take into account any commissions that are taken on every trade. We did not consider any other parameters that influence other market moves that might correlate. Some well-designed feature engineering would be very impactful here. Also, we can not forget that markets are highly influenced by many human behaviors and psychology. To have the fuller view on things that influence prices we need to analyze data from social networks and news platforms. Even simple sentiment analysis could be a game-changer.
As you can see Deep Reinforcement Learning algorithm showed some promising results. To be successful during live trading it needs to be more complex to model a more complicated system. With building proper pipelines of data, good feature engineering, and by my mind the most important – properly analyze human psychology based behaviors might give the best results. Surely it is not possible to trade always optimal. There might occur some situations that never happened before and no human or algorithm might predict this. A good example could be a recent crisis caused by the COVID-19 pandemic. This crisis was different than any other in the past. The reasons, results, and behaviors were different than in any other situation in the past. Despite this kind of situations that are unavoidable DRL is a really good choice and probably will outperform all other algorithms that rely on more stiff, human-created rules.
I would like to finish this article by citing DeepMinds CEO and co-founder Demis Hassabis:
“The whole beauty of this kind of algorithms is that because they are learning from themselves they can go beyond what we, as the programmers know how to do and allow us to make new breakthroughs in areas of science and medicine”
Deep Reinforcement Learning is very promising and it is the first step in general-purpose algorithms and Artificial General Intelligence. There still needs to be done a lot of new research in this field but certainly, it can already be applied in many challenging domains like stock market trading strategies, scientific discoveries, or breakthroughs in medicine. But the potential for the future is even bigger.
Resources:
[1] Deep Reinforcement Learning Hands-On, By Maxim Lapan, https://www.packtpub.com/product/deep-reinforcement-learning-hands-on/9781788834247
[2] Hands-On Machine Learning with Scikit-Learn & TensorFlow, Aurélien Géron
[3] https://www.mdpi.com/1424-8220/20/5/1359/htm
[4] https://towardsdatascience.com/@notadamking
[6] https://deepmind.com/blog/article/AlphaFold-Using-AI-for-scientific-discovery
[7] https://stable-baselines.readthedocs.io/en/master/
[8] https://openai.com/blog/openai-baselines-ppo/
[9] https://www.youtube.com/watch?v=5P7I-xPq8u8
[10] https://www.youtube.com/watch?v=bRfUxQs6xIM&list=PLqYmG7hTraZBKeNJ-JE_eyJHZ7XgBoAyb&index=6